Agentified Agent Assessment (AAA) & AgentBeats
Towards Agentified Agent Assessment (AAA)
A New Paradigm for Open, Standardized, Reproducible Agent Evaluation
Abstract
As agent systems grow more capable, evaluating them efficiently has become a central challenge. Traditional benchmarks like Tau-Bench, SWE-Bench, and BrowserGym primarily test LLMs under fixed harnesses, making it difficult to assess agents with diverse workflows, control loops, or architectures. These setups often require heavy custom integration and result in mismatches between test and production behavior, undermining the reliability of results. To overcome these issues, we propose Agentified Agent Assessment (AAA)—a framework where evaluation itself is handled by specialized “assessor agents” that issue tasks, collect results, and compute performance metrics. Built on open standards such as A2A for task management and MCP for tool access, AAA enables any compliant agent to participate in standardized, reproducible, and interoperable assessments.
Building on AAA, the AgentBeats platform provides the infrastructure to manage and execute these assessments at scale. It hosts both assessor agents and assessee agents, offering real-time observability, leaderboards, and a unified SDK for easy integration. By aligning testing conditions with production realities, AgentBeats reduces engineering overhead while supporting multi-agent evaluations natively. Together, AAA and AgentBeats form the foundation for open, reproducible, and transparent agent evaluation—empowering researchers and developers to measure progress fairly and accelerate innovation across the agent ecosystem.
Agent systems have been advancing rapidly, and so has the evaluation of these systems. Assessing agents has become a central challenge in both industry and academic research—after all, you can only improve what you can measure.
There have been numerous benchmarks designed to evaluate agents—such as Tau-Bench, SWE-Bench, OSWorld, and BrowserGym. However, existing benchmarks often face three key limitations:
- LLM-centric design and fixed harnesses. Most benchmarks primarily test the underlying LLMs, assuming a fixed harness or execution loop. While switching to a different model may only require changing a model identifier, evaluating agents with distinct harnesses—such as alternative control flows, pre-defined workflows, or multi-agent structures—remains unsupported.
- High integration overhead. Because of these rigid interfaces, adapting an existing agent to a given benchmark often requires significant custom integration. A production-grade agent tested across ten benchmarks may need ten separate adaptations, each introducing redundant engineering effort.
- Test-production mismatch. The customization required for benchmarking often leads to discrepancies between the tested agent and its production counterpart. Consequently, performance metrics may fail to capture behaviors or risks that emerge in real-world operation.
To address these issues, we propose Agentified Agent Assessment (AAA) — a new paradigm for open, standardized, and reproducible agent evaluation. AAA introduces three core features:
- Agentified evaluation. The central idea is to create specialized assessor agents that evaluate other assessee agents. An assessor agent encapsulates the benchmark environment, issues test tasks, collects results, and computes performance metrics. By structuring the assessment itself as an agent, AAA enables standardization and unified management of evaluation processes.
- Standardization. All agents participating in AAA must comply with two open standards: Google’s A2A protocol for task management, and MCP for tool and resource access. Any agent conforming to these standards can seamlessly participate in any AAA evaluation, ensuring interoperability and modularity across systems.
- Reproducibility. AAA is designed not only to make evaluations reproducible, but also easily reproducible. This is achieved through a new control protocol governing the full assessment lifecycle and an open platform that manages both agents and assessments following the AAA principles.
The table below compares traditional agent benchmarking with our proposed AAA paradigm. AAA broadens evaluation coverage, enhances interoperability through standardized interfaces, improves realism by aligning with production conditions, and naturally supports multi-agent evaluations.
| Traditional Agent Benchmarking | Agentified Agent Assessment (AAA) | |
|---|---|---|
| Evaluation target | Primarily focused on LLMs with fixed harnesses | Any agent conforming to the A2A protocol |
| Interface | Benchmark-specific and implementation-dependent | Standardized, A2A for task management and MCP for tool access |
| Realism | Prone to test-production mismatch; mainly used for reference | Directly reflects production-level performance |
| Multi-agent assessment support | Difficult, requiring bespoke integrations | Natively supported through standardized interfaces and platform-level coordination |
Comparison with Traditional Benchmarks
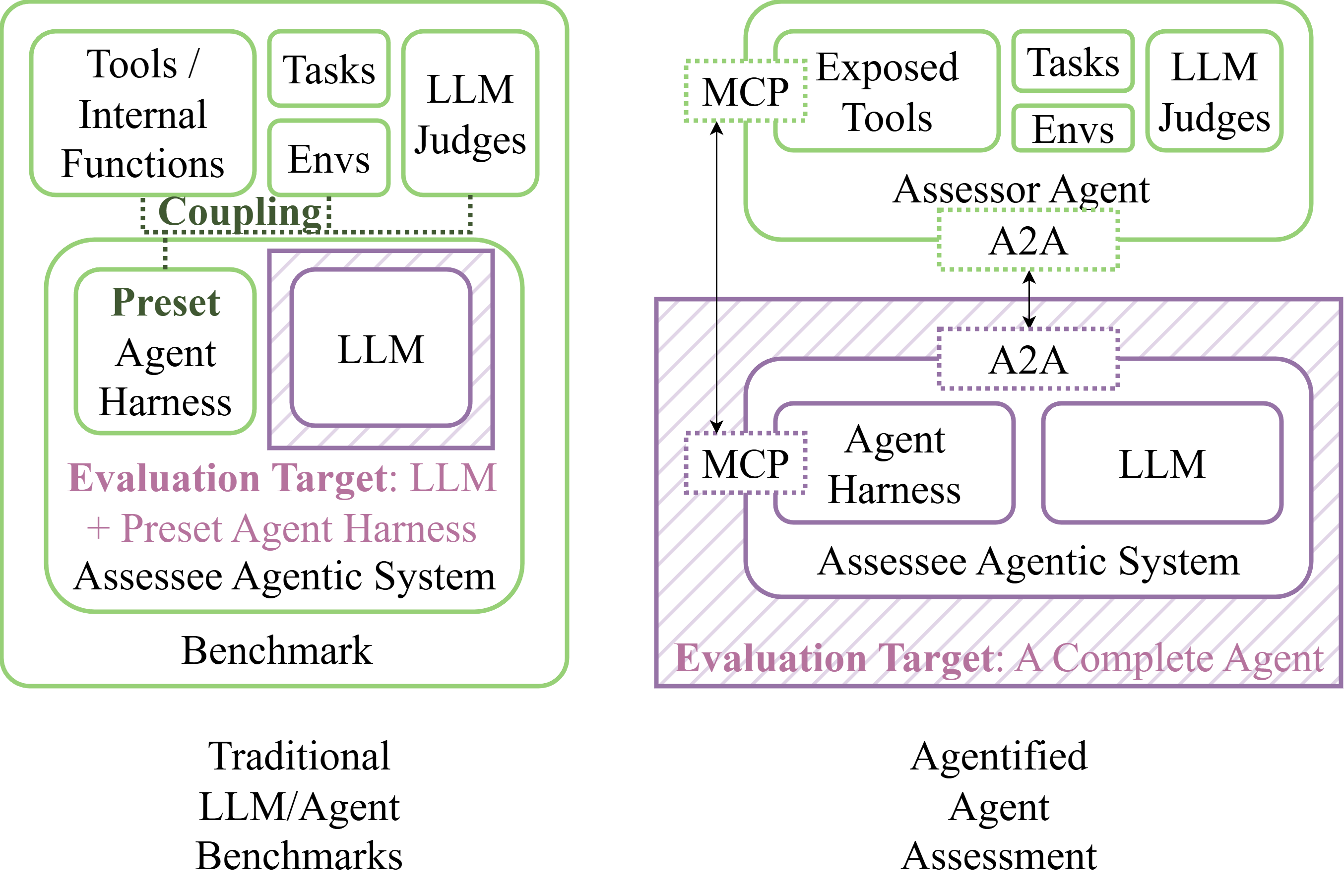
Traditional benchmarks often focus on evaluating LLMs within fixed harnesses. The evaluation target is usually either the LLM itself, or a few preset agent harnesses. In contrast, AAA allows any agent that conforms to the A2A protocol and MCP to be evaluated, regardless of its internal architecture or control flow.
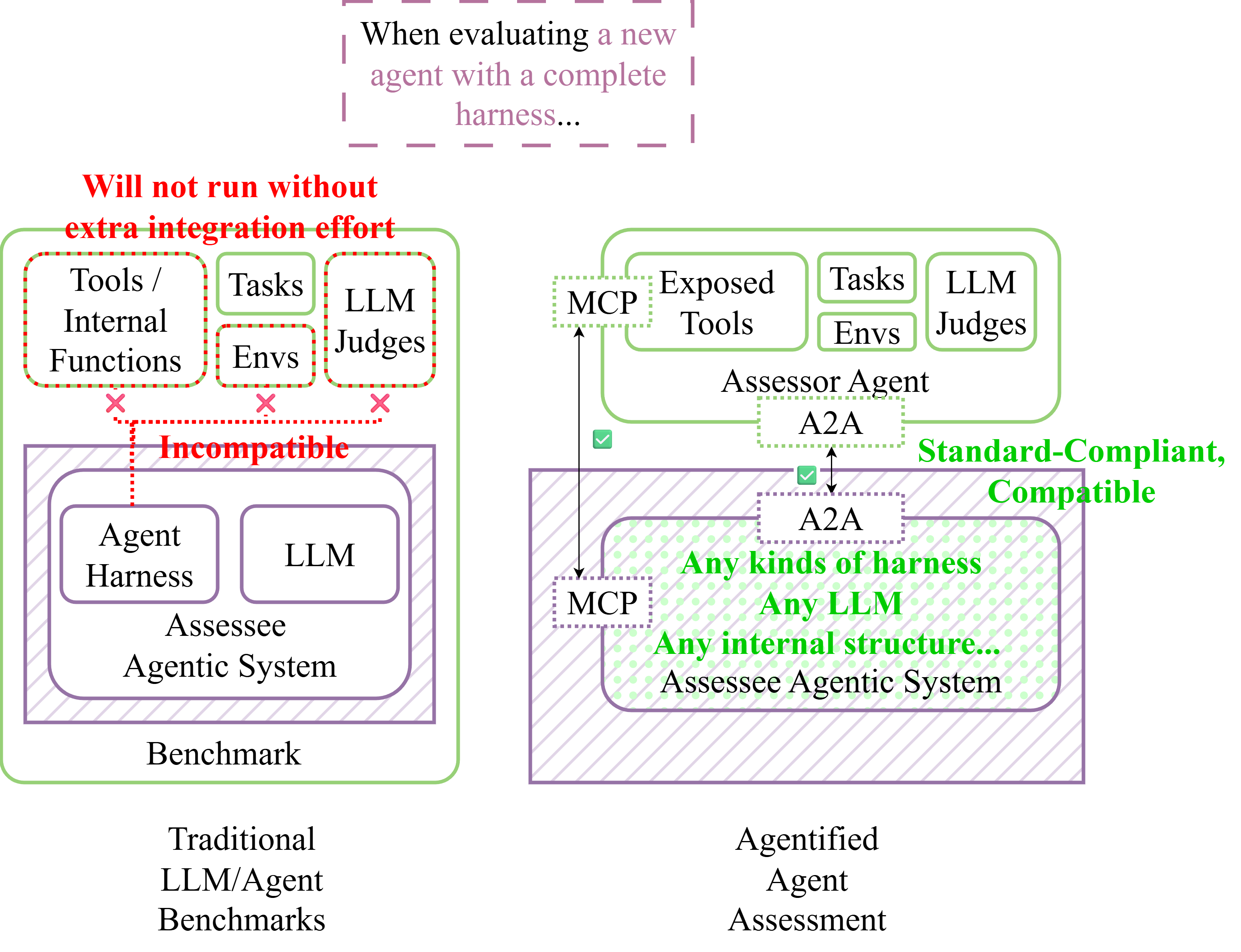
When testing a new agent in a benchmark that comes with its own built-in harness, developers often face significant integration work because the harness is tightly coupled with the rest of the benchmark logic. In contrast, AAA removes this coupling: as long as an agent implements the A2A protocol, it can be evaluated directly—without any custom integration or benchmark-specific adaptation.
Practicing AAA: The AgentBeats Platform
Despite growing recognition of the importance of agent evaluation, creating effective and impactful assessments remains challenging for both researchers and practitioners. Even with a clear and innovative benchmark concept, two major obstacles often hinder progress:
- System implementation complexity. Designing an assessment—collecting data, defining metrics, and implementing workflows—is already demanding. On top of that, developers must integrate multiple LLMs, navigate diverse agent frameworks, and manage observability, environment setup, and documentation. Hosting public competitions adds further burden, requiring infrastructure for agent deployment, monitoring, and leaderboard management.
- Lack of openness and adoption. Even a well-engineered benchmark struggles to gain traction without a unified platform that transforms research prototypes into widely accessible, reusable evaluations.
To address these challenges, we introduce the AgentBeats platform, built upon the AAA paradigm. AgentBeats will serve as a centralized infrastructure for managing and executing agent assessments. It targets to provide hosting for agents, real-time observability, and registries for available agents and assessments. The platform will also maintain public leaderboards summarizing performance across standardized metrics. In addition, AgentBeats targets to offer a dedicated SDK that simplifies the development of both assessor and assessee agents. The SDK enables developers to easily register agents, access platform features, and integrate seamlessly with the A2A and MCP protocols, thereby lowering the entry barrier for creating new, reproducible agent evaluations.
Together, we can build a foundation where every agent can be assessed fairly, reproducibly, and transparently—accelerating both research and real-world deployment.